在上一节中,我们通过一个框架爬虫获取到了交易猫上我们所需的商品链接,但是游戏账号重要的是账号里的截图啊,毕竟“无图无真相”嘛。Scrapy提供了内置的专门处理下载的Pipelines,包括文件下载(Files Pipeline)和图片下载( Images Pipeline)。使用这两个内置的pipeline下载文件和图像,具有异步和多线程的功能,配合恰当的中间件,可以实现非常高效的下载。下面将使用 Images Pipeline 将上一节中我们获取到的交易猫商品中的“商品介绍”里的图片下载到本地计算机。
0x00
首先我们需要改写一下之前的Spider和Pipeline。因为我们需要先筛选出我们需要的商品,然后解析该商品页面获取到游戏截图的URL。根据上一节的代码,我们将筛选过程放在了Pipeline中,而Pipeline的返回值只能是Item和DropItem异常,这样我们就无法将筛选后的商品URL存入Scheduler以实现下载。因此,我们需要删除原来的 MissPipeline 然后将筛选规则写在sipder中。
我们在parse方法中的每条 标签分析中添加以上代码,便可以判断该商品是否是我们所需要的,然后将每个所需商品的URL构造成Request发送给Scheduler。注意!这里的回调函数不再是**parse,而是good_parse**,也就是我们用于解析商品页面的方法。
|
|
然后我们再写一个方法,也就是上面的 good_parse 用于解析出商品链接并将其保存在Item中名为 image_urls 键中,方便后续 Images Pipeline 执行下载操作。
|
|
这里我们还使用了一个css选择器的高级用法。ul[class=“slider-items”] 表示选取class属性为 slider-items 的且名为_ul_的标签,这样写是不是比xpath方便很多 (~^O^~)
0x01
然后正式开始折腾Images Pipeline。
首先定义存储文件的路径,我们需要再 **settings.py**中定义一个名为 IMAGES_STORE的变量。
IMAGES_STORE = ‘./images’
这里将路径定义为当前路径下的images子文件夹,框架会自动完成创建文件夹等过程,并将下载的文件自动保存至该文件夹。
然后我们需要在 _items.py _中添加一个字段以储存image_urls
|
|
内置的 Images Pipeline 会默认读取Item的image_urls字段,并认为该字段是一个列表形式,并遍历该字段,取出每个URL进行图片下载,并将下载是否成功,图片path,checksum等信息填充至images字段。当然,若是你生成的Item的图片链接字段并不是 image_urls 字段表示的,或者不是列表形式等情况,也可以通过重写Images Pipeline的部分方法,重写定义下载的部分逻辑以进行下载。
如此如此,我们启动Images Pipeline后便可以实现下载所有符合条件的商品的游戏截图,但是我们又面临了一个问题——从头至尾,我们所使用的全都是一类Item,因此,返回的Item,有的保存着商品的**name和URL**,而有的又仅有image_urls,这会给我们最后的保存数据带来不小的难度。对于这个问题,有两个解决方案:
- 1.再定义一个Scrapy.Item类,将Image_urls保存至新类生成的Item中。
- 2.再写一个Pipeline,洗去已经完成了图片下载的Item
这里我们采取第二个方案,我们重写 MissPipeline方法,以洗去那些已经完成了图片下载的Item。因为这些Item并没有**name这个key**,我们可以以此为判断依据,将没有**name的Item进行Drop**。
|
|
然后再**settings.py**中将这两个Pipeline启动起来,但要注意优先级。
|
|
‘scrapy crawl jiaoym’ 启动爬虫便可以看到生成了一个images/full目录,并将一张张图片下载到该目录下。
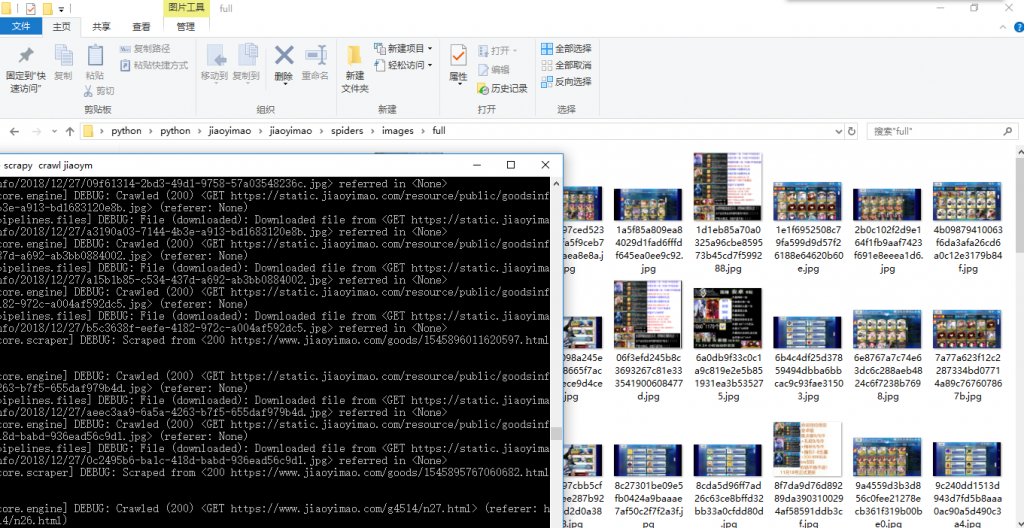
**Okey!我们成功用了Images Pipeline**下载了交易猫上的商品截图。
最后附上Scrapy media-pipeline的官方文档链接,送给那些爱钻研的小伙伴去研究更多的姿势。