本来这篇文章5月就写好了,然后因为各种各样的事情咕了好久,以至于今天才发出来。
虚假控制流,Bogus-Control-Flow(BCF),该⽅法通过在当前基本块之前添加⼀个基本块来修改函数调⽤图。这个新的基本块包含⼀个不透明的谓词,然后有条件地跳转到原始基本块。原始的基本块也将被克隆并填充以随机选择的垃圾指令,这⾥和我们在CTF中的⼀些看到的很多if…else…语句相对应了,中间会有很多的分⽀,有⼀个是正确的
-mllvm -bcf : activates the bogus control flow pass
-mllvm -bcf_loop=3 : if the pass is activated, applies it 3 times on a function. Default: 1
-mllvm -bcf_prob=40 : if the pass is activated, a basic bloc will be obfuscated with a probability of 40%. Default: 30
OLLVM虚假控制流混淆源码位置:OLLVMCODE\lib\Transforms\Obfuscation\BogusControlFlow.cpp
0x01 runOnFunction函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
virtual bool runOnFunction(Function &F) {
// Check if the percentage is correct
if (ObfTimes <= 0) { // 对函数混淆的次数
errs() << "BogusControlFlow application number -bcf_loop=x must be x > 0";
return false;
}
// Check if the number of applications is correct
if (!((ObfProbRate > 0) && (ObfProbRate <= 100))) { // 对函数混淆的概率
errs() << "BogusControlFlow application basic blocks percentage "
"-bcf_prob=x must be 0 < x <= 100";
return false;
}
// If fla annotations
if (toObfuscate(flag, &F, "bcf")) { // 检查函数是否需要进行虚假控制流混淆
bogus(F);
doF(*F.getParent());
return true;
}
return false;
} // end of runOnFunction()
|
其中,ObfProbRate和ObfTimes这两个参数分别是执行opt时传入的
1
2
3
4
5
6
7
8
9
10
11
12
|
static cl::opt<int>
ObfProbRate("bcf_prob",
cl::desc("Choose the probability [%] each basic blocks will be "
"obfuscated by the -bcf pass"),
cl::value_desc("probability rate"), cl::init(defaultObfRate),
cl::Optional);
static cl::opt<int>
ObfTimes("bcf_loop",
cl::desc("Choose how many time the -bcf pass loop on a function"),
cl::value_desc("number of times"), cl::init(defaultObfTime),
cl::Optional);
|
通过该函数的分析可知,混淆的关键函数是bogus和doF这两个函数
0x02 toObfuscate函数
toObfuscate 判断当前操作的函数是否要进行某种混淆(fla, sub, bcf)
o-llvm 开启混淆有两种方法:
1. 命令行参数指定全局混淆
2. Functions-annotations 指定局部混淆
局部混淆 annotations 修饰方法例子如下:
int func() __attribute((__annotate__(("fla"))));
toObfuscate 先判断 annotations 标志,再判断全局标记。llvm 中用 readAnnotate(f) 来获取函数的 annotations
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 优先判断是否有noattr的标志,如果有则不混淆 如:nobcf nosub nofla
// We have to check the nofla flag first
// Because .find("fla") is true for a string like "fla" or
// "nofla"
if (readAnnotate(f).find(attrNo) != std::string::npos) {
return false;
}
// 判断是否有添加混淆的annotations
// If fla annotations
if (readAnnotate(f).find(attr) != std::string::npos) {
return true;
}
// 判断是否有全局混淆的flag参数
// If fla flag is set
if (flag == true) {
return true;
}
|
0x03 bogus函数
开头部分还是对那两个参数检查
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// 又一次检查ObfProbRate和ObfTimes参数
if (ObfProbRate < 0 || ObfProbRate > 100) {
DEBUG_WITH_TYPE("opt", errs()
<< "bcf: Incorrect value,"
<< " probability rate set to default value: "
<< defaultObfRate << " \n");
ObfProbRate = defaultObfRate;
}
DEBUG_WITH_TYPE("opt", errs()
<< "bcf: How many times: " << ObfTimes << "\n");
if (ObfTimes <= 0) {
DEBUG_WITH_TYPE("opt", errs()
<< "bcf: Incorrect value,"
<< " must be greater than 1. Set to default: "
<< defaultObfTime << " \n");
ObfTimes = defaultObfTime;
}
|
然后下面是一个 do{…}while(–NumObfTimes > 0); 的大循环,可以看到是以混淆次数为依据的。里面除了大量的debug语句外,真正有用的代码就一点点,就两个循环。第一个循环遍历该函数所有基本块,并存入一个list中
1
2
3
4
5
|
// Put all the function's block in a list
std::list<BasicBlock *> basicBlocks;
for (Function::iterator i = F.begin(); i != F.end(); ++i) { // 将所有基本块存入basicBlocks
basicBlocks.push_back(&*i);
}
|
第二个循环则是从basicBlocks list中取基本块,并以ObfProbRate为依据进行概率混淆,即对基本块调用了addBogusFlow函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
while (!basicBlocks.empty()) {
NumBasicBlocks++;
// Basic Blocks' selection
if ((int)llvm::cryptoutils->get_range(100) <= ObfProbRate) { // 以obfProbRate概率混淆
BasicBlock *basicBlock = basicBlocks.front();
addBogusFlow(basicBlock, F); // 调用addBogusFlow进行虚假控制流混淆
}
// remove the block from the list
basicBlocks.pop_front();
if (firstTime) { // first time we iterate on this function
++InitNumBasicBlocks;
++FinalNumBasicBlocks;
}
} // end of while(!basicBlocks.empty())
|
0x04 addBogusFlow函数 Part1
首先通过getFirstNonPHIOrDbgOrLifetime函数和splitBasicBlock函数把BasicBlock分成了两部分,第一部分只包含PHI Node和一些调试信息,其中Twine可以看做字符串,即新产生的BasicBlock的名称
1
2
3
4
5
6
7
8
9
10
|
BasicBlock::iterator i1 = basicBlock->begin();
if (basicBlock->getFirstNonPHIOrDbgOrLifetime())
i1 = (BasicBlock::iterator)basicBlock->getFirstNonPHIOrDbgOrLifetime();
Twine *var;
var = new Twine("originalBB"); // 新产生的BasicBlock的名称
BasicBlock *originalBB = basicBlock->splitBasicBlock(i1, *var);
// Creating the altered basic block on which the first basicBlock will jump
Twine *var3 = new Twine("alteredBB");
BasicBlock *alteredBB = createAlteredBasicBlock(originalBB, *var3, &F); // 产生了一个新的基本块
|
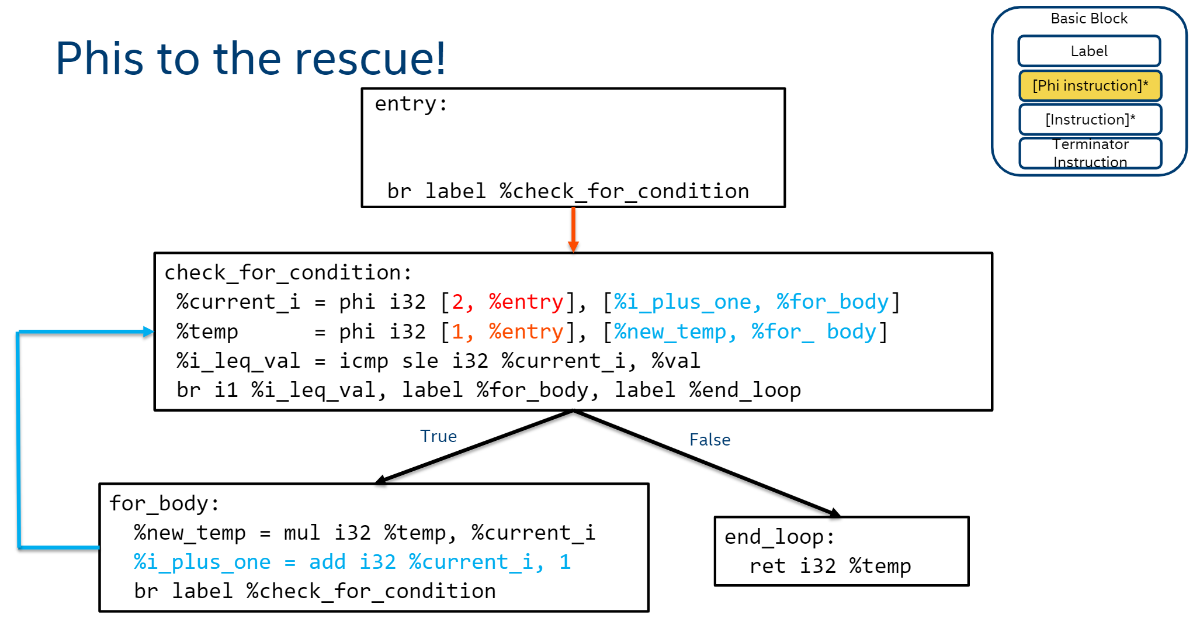
这里先补充讲一下PHI Node是什么。所有 LLVM 指令都使用 SSA (Static Single Assignment,静态一次性赋值) 方式表示,即所有变量都只能被赋值一次,这样做主要是便于后期的代码优化。如下图,%temp的值被赋值成1后就永远是1了
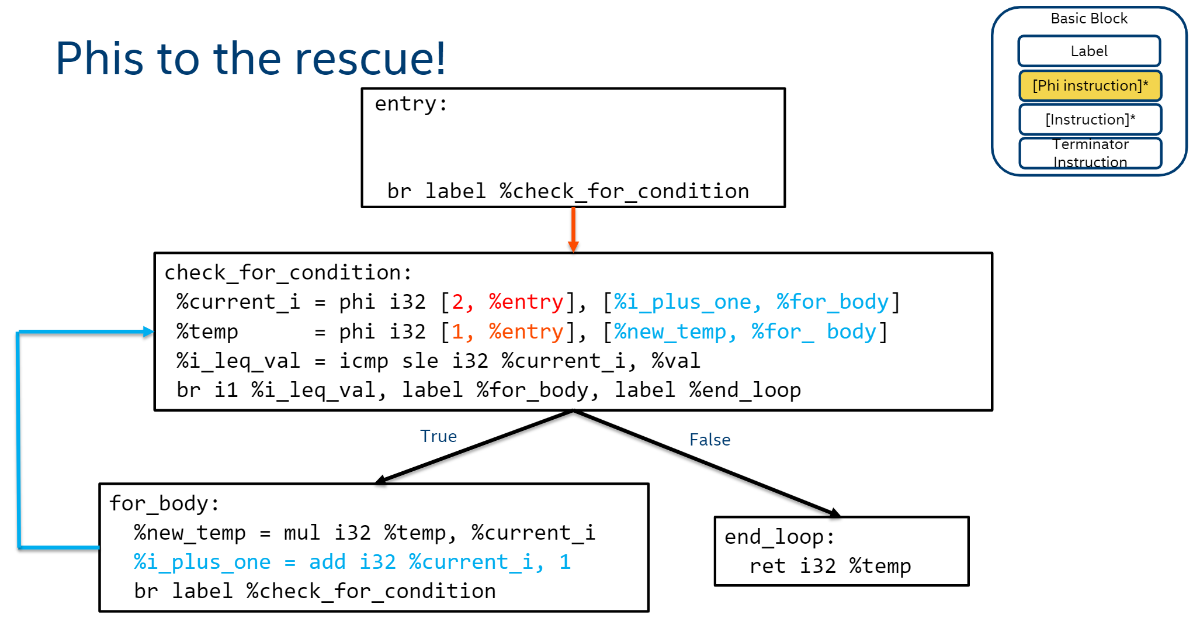
PHI Node是一条可以一定程度上绕过SSA机制的指令,它可以根据不同的前驱基本块来赋值(有点像三元运算符)。如下图,如果PHI Node的前驱基本块是entry,则将current_i赋值为2,如果是for_body,则赋值为%i_plus_one
做了PHINode的科学介绍,但可能还是很抽象,这splite出来的node块到底包含哪些东西。其实做一下实验就知道了。写一个C程序
1
2
3
4
5
|
int main(int argc, char* argv[]) {
int a = 1;
std::cout << "Main" << std::endl;
return 0;
}
|
分别编译一份经过bcf混淆和没有混淆的二进制程序,对比main函数。左上角的图是没有经过混淆的,右边的则是经过混淆后的main控制流反汇编图。但是要注意,OLLVM的混淆Pass是先于编译器优化的,所以看到的汇编会稍有不同。
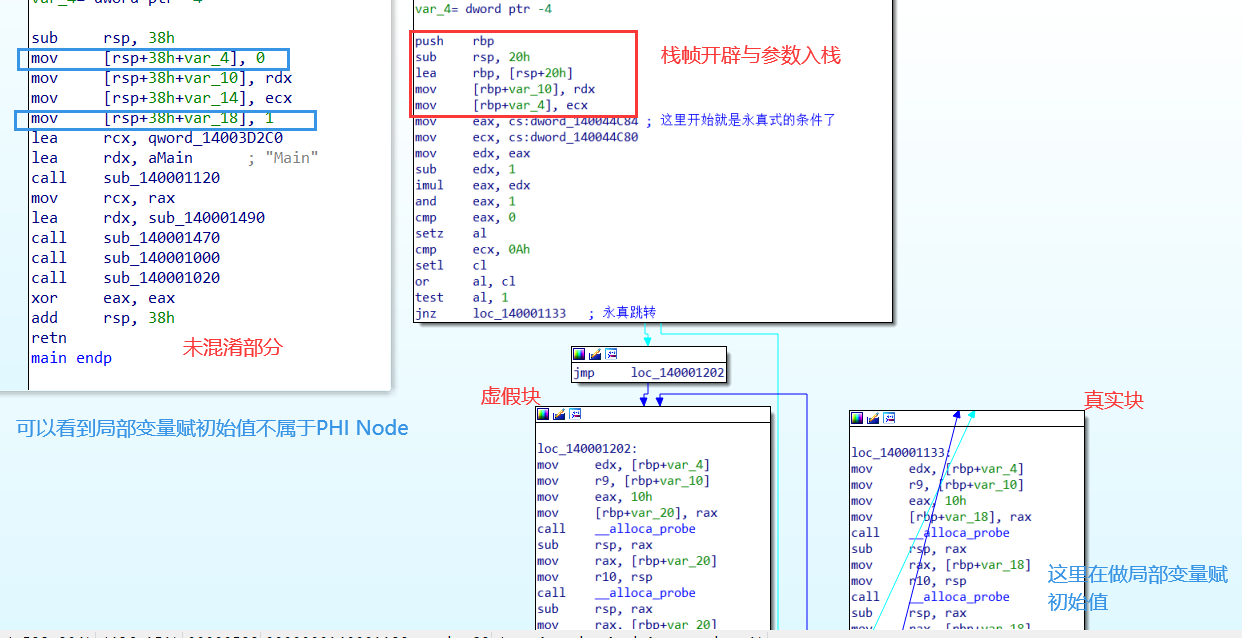
根据前面阅读源码后对混淆算法理解,可以看出来,整一个Main函数的代码块,头上的 push rbp; sub rsp; mov参数入栈等操作,与Main函数主体被分割开来了,并插入了用真条件做了跳转。不难理解,被分割出来的这一部分,就是前面getFirstNonPHIOrDbgOrLifetime()函数得到的部分,也就是PHI Node。
下面先进入createAlteredBasicBlock函数看一下这个新产生的基本块有什么不同
0x05 createAlteredBasicBlock函数
函数的开头首先会对传入的基本块进行克隆
1
2
3
|
// Useful to remap the informations concerning instructions.
ValueToValueMapTy VMap; // VMap会保存新旧指令的映射关系
BasicBlock *alteredBB = llvm::CloneBasicBlock(basicBlock, VMap, Name, F); // 对传入的基本块进行克隆
|
但是CloneBasicBlock克隆出来的基本块不是完全的克隆,是存在问题的,所以需要进行一些处理。
首先他不会对指令的操作数进行替换
orig:
%a = ...
%b = fadd %a, ...
clone:
%a.clone = ...
%b.clone = fadd %a, ... ; Note that this references the old %a and not %a.clone!
所以之后要通过VMap对所有操作数进行映射,使其恢复正常,VMap中保存着新旧指令的映射关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// Remap operands.
BasicBlock::iterator ji = basicBlock->begin(); // VMap对所有操作数进行映射,使其恢复正常
for (BasicBlock::iterator i = alteredBB->begin(), e = alteredBB->end();
i != e; ++i) {
// Loop over the operands of the instruction
for (User::op_iterator opi = i->op_begin(), ope = i->op_end(); opi != ope;
++opi) {
// get the value for the operand
Value *v = MapValue(*opi, VMap, RF_None, 0);
if (v != 0) {
*opi = v;
DEBUG_WITH_TYPE("gen",
errs() << "bcf: Value's operand has been setted\n");
}
}
|
并且CloneBasicBlock不会对PHI Node进行任何处理,PHI Node的前驱块仍然是原始基本块的前驱块,但是新克隆出来的基本块并没有任何前驱块,所以我们要对PHI Node的前驱块进行remap,使其前驱块remap到nullptr
1
2
3
4
5
6
7
8
|
if (PHINode *pn = dyn_cast<PHINode>(i)) { // 对克隆出来块的PHINode前驱remap到nullprt
for (unsigned j = 0, e = pn->getNumIncomingValues(); j != e; ++j) {
Value *v = MapValue(pn->getIncomingBlock(j), VMap, RF_None, 0);
if (v != 0) {
pn->setIncomingBlock(j, cast<BasicBlock>(v));
}
}
}
|
下面是恢复Metadata信息和debug信息
1
2
3
4
5
6
7
|
// Remap attached metadata.
SmallVector<std::pair<unsigned, MDNode *>, 4> MDs;
i->getAllMetadata(MDs); // 恢复Metadata信息
DEBUG_WITH_TYPE("gen", errs() << "bcf: Metadatas remapped\n");
// important for compiling with DWARF, using option -g.
i->setDebugLoc(ji->getDebugLoc()); // 恢复Debug信息
ji++;
|
到这里为止,才是真正完成了一个基本块的克隆。之后是往基本块里添加垃圾指令,这里大概的思路就是往基本块里插入一些没用的赋值指令,或者修改cmp指令的条件,BinaryOp大概指的是add、mul、cmp这类运算指令。后面全部部分就是随机化生成并插入垃圾指令。 总的来说createAlteredBasicBlock函数克隆了一个基本块,并且往这个基本块里添加了一些垃圾指令。
0x06 addBogusFlow函数 Part2
现在我们有了一个原始基本块originalBB,和一个克隆出的基本块alteredBB,以及一个只包含PHI Node和Debug信息的基本块basicBlock(就是一开始分离出来的那个)
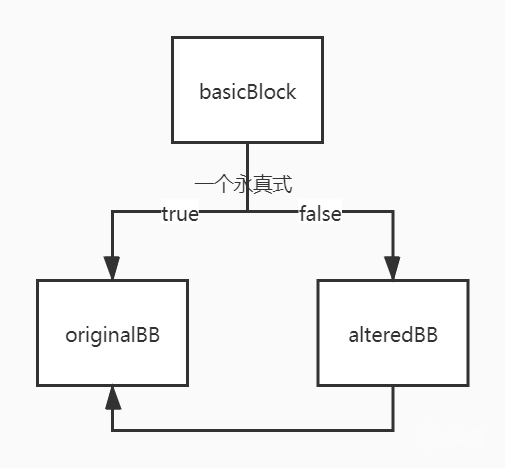
接下来会删除了basciBlock和alteredBB末尾的跳转,并添加了新的分支指令。 *FCmpInst * condition = new FCmpInst(*basicBlock, FCmpInst::FCMP_TRUE , LHS, RHS, *var4)*是一个永真的条件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
alteredBB->getTerminator()->eraseFromParent(); // 删除alteredBB末尾跳转
basicBlock->getTerminator()->eraseFromParent(); // 删除basicBlock末尾跳转
Value *LHS = ConstantFP::get(Type::getFloatTy(F.getContext()), 1.0);
Value *RHS = ConstantFP::get(Type::getFloatTy(F.getContext()), 1.0);
DEBUG_WITH_TYPE("gen", errs() << "bcf: Value LHS and RHS created\n");
// The always true condition. End of the first block
Twine *var4 = new Twine("condition");
FCmpInst *condition =
new FCmpInst(*basicBlock, FCmpInst::FCMP_TRUE, LHS, RHS, *var4); // 添加一个永真条件
// Jump to the original basic block if the condition is true or
// to the altered block if false.
BranchInst::Create(originalBB, alteredBB, (Value *)condition, basicBlock); // 添加分支指令,为真时basicBlock->originalBB; 为假时basicBlock->alteredBB
// The altered block loop back on the original one.
BranchInst::Create(originalBB, alteredBB); // 将alteredBB块指向originalBB块
|
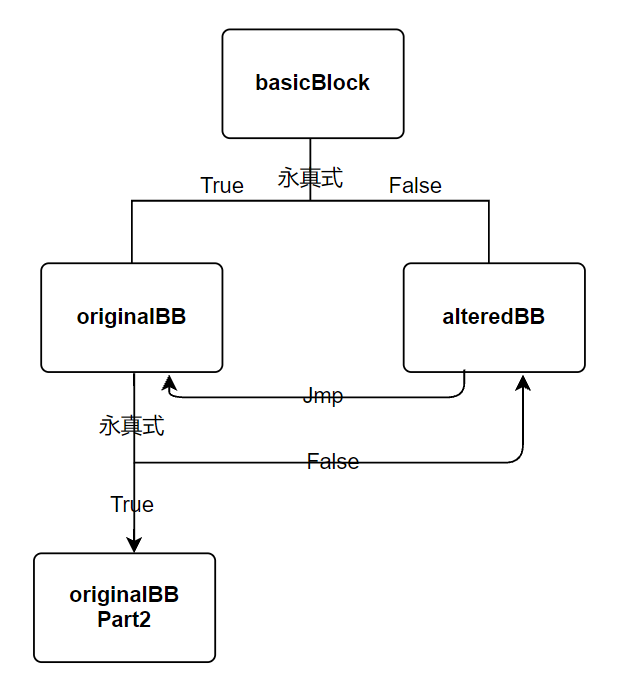
然后下面又是一波类似的操作,这里会截取的originalBB结尾的跳转指令作为一个新的基本块originalBBPart2,并添加一个永真条件。条件为真时,originalBB块会跳转到originalBBPart2走真正的跳转指令,条件为假时,originalBB块会跳转到alteredBB虚假块。
1
2
3
4
5
6
7
8
9
10
11
|
BasicBlock::iterator i = originalBB->end();
// Split at this point (we only want the terminator in the second part)
Twine *var5 = new Twine("originalBBpart2");
BasicBlock *originalBBpart2 = originalBB->splitBasicBlock(--i, *var5); // 截取的originalBB结尾的跳转指令作为一个新的基本块originalBBPart2
originalBB->getTerminator()->eraseFromParent(); // 删除originalBB块末尾跳转
Twine *var6 = new Twine("condition2");
FCmpInst *condition2 =
new FCmpInst(*originalBB, CmpInst::FCMP_TRUE, LHS, RHS, *var6); // 添加永真条件
BranchInst::Create(originalBBpart2, alteredBB, (Value *)condition2, // 添加分支指令,为真时basicBlock->originalBB; 为假时basicBlock->alteredBB
originalBB);
|
经过这一步后,流程图应该是这样的
0x07 doF函数
在runOnFunction函数,除了调用bogus函数外,还调用doF函数。通过注释可以大致了解到,doF函数会修改永真式使其变得更加复杂,并会擦除所有基本块、指令和函数的名称。
函数开头先初始化两个全局变量
1
2
3
4
5
6
7
8
9
10
11
|
// The global values
Twine *varX = new Twine("x"); // 初始化两个全局变量
Twine *varY = new Twine("y");
Value *x1 = ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false);
Value *y1 = ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false);
GlobalVariable *x =
new GlobalVariable(M, Type::getInt32Ty(M.getContext()), false,
GlobalValue::CommonLinkage, (Constant *)x1, *varX);
GlobalVariable *y =
new GlobalVariable(M, Type::getInt32Ty(M.getContext()), false,
GlobalValue::CommonLinkage, (Constant *)y1, *varY);
|
然后会遍历模块中所有函数的所有指令,遇到条件为永真式的条件跳转时将跳转指令BranchInst(分支指令)存储到toEdit向量中,将比较指令FCmpInst(条件)存储到toDelete向量中。然后这里删除所有基本块和指令名称的代码被注释掉了,不知道为啥
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
std::vector<Instruction *> toEdit, toDelete;
BinaryOperator *op, *op1 = NULL;
LoadInst *opX, *opY;
ICmpInst *condition, *condition2;
// Looking for the conditions and branches to transform
for (Module::iterator mi = M.begin(), me = M.end(); mi != me; ++mi) { // 遍历所有Module
for (Function::iterator fi = mi->begin(), fe = mi->end(); fi != fe; // 遍历所有函数
++fi) {
// fi->setName(""); // 删除所有函数名称
Instruction *tbb = fi->getTerminator(); // 获得末尾跳转指令
if (tbb->getOpcode() == Instruction::Br) {
BranchInst *br = (BranchInst *)(tbb);
if (br->isConditional()) {
FCmpInst *cond = (FCmpInst *)br->getCondition();
unsigned opcode = cond->getOpcode();
if (opcode == Instruction::FCmp) {
if (cond->getPredicate() == FCmpInst::FCMP_TRUE) {
DEBUG_WITH_TYPE("gen",
errs() << "bcf: an always true predicate !\n");
toDelete.push_back(cond); // The condition
toEdit.push_back(tbb); // The branch using the condition
}
}
}
}
/* 删除所有基本块和指令名称的代码被注释掉了
for (BasicBlock::iterator bi = fi->begin(), be = fi->end() ; bi != be;
++bi){ bi->setName(""); // setting the basic blocks' names
}
*/
}
}
|
下面是遍历toEdit列表(永真式的末尾跳转指令列表),添加新的条件跳转,删除旧的条件跳转,注释里的条件给错了,从代码来看应该是if y < 10 || x*(x-1) % 2 == 0,不过也差不多:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// Replacing all the branches we found
for (std::vector<Instruction *>::iterator i = toEdit.begin();
i != toEdit.end(); ++i) {
// if y < 10 || x*(x-1) % 2 == 0
opX = new LoadInst((Value *)x, "", (*i));
opY = new LoadInst((Value *)y, "", (*i));
op = BinaryOperator::Create(
Instruction::Sub, (Value *)opX,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 1, false), "",
(*i));
op1 =
BinaryOperator::Create(Instruction::Mul, (Value *)opX, op, "", (*i));
op = BinaryOperator::Create(
Instruction::URem, op1,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 2, false), "",
(*i));
condition = new ICmpInst(
(*i), ICmpInst::ICMP_EQ, op,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false));
condition2 = new ICmpInst(
(*i), ICmpInst::ICMP_SLT, opY,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 10, false));
op1 = BinaryOperator::Create(Instruction::Or, (Value *)condition,
(Value *)condition2, "", (*i));
BranchInst::Create(((BranchInst *)*i)->getSuccessor(0),
((BranchInst *)*i)->getSuccessor(1), (Value *)op1,
((BranchInst *)*i)->getParent());
DEBUG_WITH_TYPE("gen", errs() << "bcf: Erase branch instruction:"
<< *((BranchInst *)*i) << "\n");
(*i)->eraseFromParent(); // erase the branch
}
|
最后会删除之前存储的FCmpInst(条件指令)
1
2
3
4
5
|
// Erase all the associated conditions we found
for (std::vector<Instruction *>::iterator i = toDelete.begin();
i != toDelete.end(); ++i) {
(*i)->eraseFromParent();
}
|
0x08 魔改思路
其实读完源码后,魔改思路还是挺多的。比如对不透明谓词可以在运行过程当中对其重新赋值,可以对其垃圾指令进行处理加花等等。
参考资料
-
OLLVM虚假控制流源码学习笔记
-
重写 OLLVM 之虚假控制流